Overview
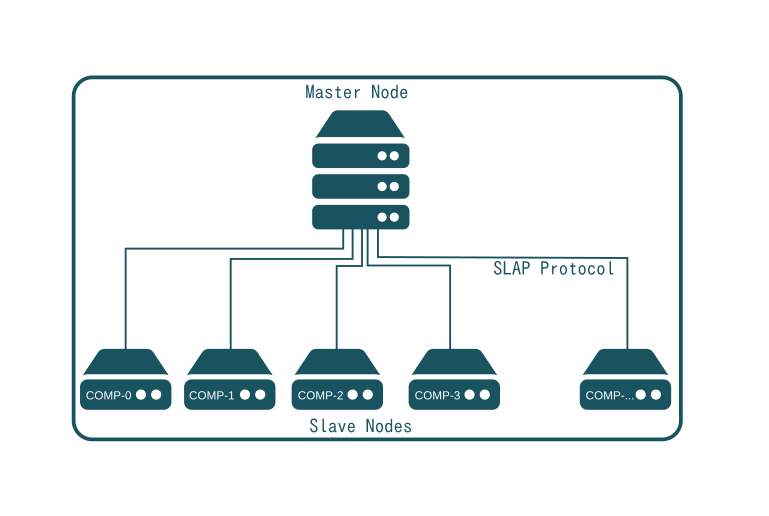
The Master contains a catalog of available Software Releases. Slave nodes request from the Master which software to install and to supply to users. Users then request services (called hosting subscriptions), which are instances of the supplied software. These are instantiated inside computer partitions available on a node. The node reports back the usage of all running instances over time to the Master who keeps track of node capacity and available software.
The Master also acts as web portal providing web services in order for users or other software to request new software instances which are instantiated and run on nodes. It does so using services provided by COMP-0 which therefore has somewhat of a special status, as it's not a standard node similar to COMP-1,2,3 providing services to users.
Master nodes are stateful. Slave nodes are stateless. More precisely, all information required to rebuild a Slave node is stored in the Master. This may for example include the url of a backup service which maintains an online copy of data so that in case of a node failure, a replacement node can be rebuilt with the same data.
It is thus very important to ensure that state data present on the Master is well secured. This can be achieved by hosting the Master node on a trusted 3rd party IAAS infrastructure with redundant resources or better by hosting multiple Master nodes on many Slave nodes located in different regions of the world based on an appropriate data redundancy heuristic.
This describes the first reflexive nature of SlapOS: A SlapOS Master is usually a running instance of a SlapOS Master software (!) instantiated on a collection of Slave nodes, which together form a trusted hosting infrastructure. In other words, SlapOS is used to host SlapOS or SlapOS is self-hosted.
Master Node - Functional Role
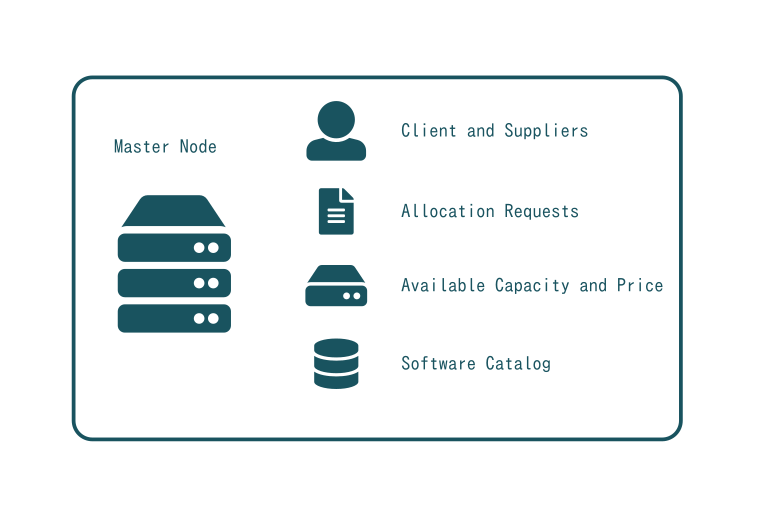
The Master node keeps track of the identity of all parties involved in (a) requesting cloud resources as well as (b) their monitoring and (c) usage billing. It therefore also includes end users and organisations which can be suppliers and/or consumers of cloud resources.
The Master manages computer partitions on all nodes. These "containers" are used to run a single software instance each which can be requested fully autonomous or through user interaction.
SlapOS generates X509 certificates for each type of identity: for users who login, for each server that contributes to the resources of SlapOS and for each running software instance that has to request/notify the Master. A SlapOS Master with a single Slave node, one user and ten computer partitions will thus generate up to 12 X509 certificates: 1 for the slave, 1 for the user and 10 for the computer partitions provided on the node.
Any user, software or Slave node with a valid X509 certificate may request resources from the SlapOS Master which acts like a back office or marketplace. Requests are recorded as if they were a resource trading contract in which a resource consumer is requesting a given resource under certain conditions. A resource could be a NoSQL storage, a KVM virtual machine, an ERP system or similar. The conditions include price, region (eg. China) or a specific hardware setup (eg. 64bit CPU). Conditions are sometimes called Service Level Agreements (SLA) in other architectures but in SlapOS they are considered more as trading specifications than hard guarantees.
By default, SlapOS Master acts as automatic marketplace. Requests are processed by trying to find a node which meets all specified conditions. The SlapOS Master thus needs to know which resources are available at a given time, at what price and with what specifications, including which software can be installed on a node and under what conditions. However, it is also possible to manually define a specific node rather than relying on the automatic marketplace logic of SlapOS Master to determine the computer to use when allocating resources.
Master Node - Software
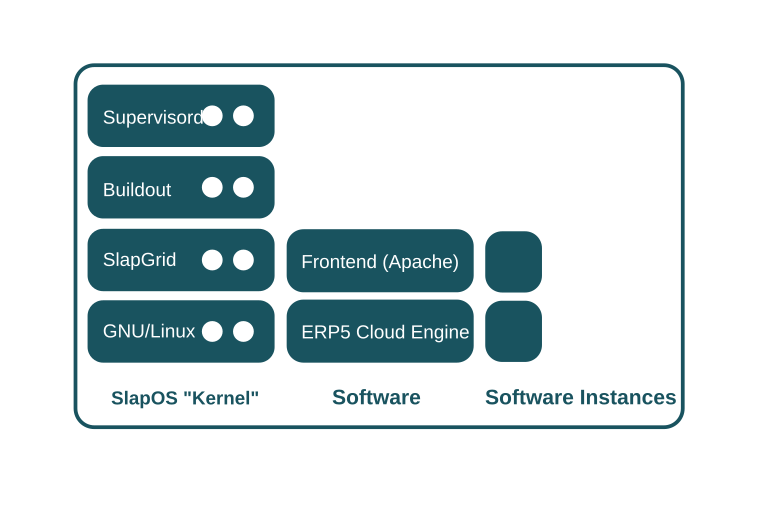
At its core, the SlapOS Master is a regular node with the SlapOS "Kernel" installed. During initial installation of the SlapOS Master, a SlapProxy ("mini"-Master) is used to setup the future SlapOS Master. In relation to the SlapProxy, the SlapOS Master is a normal node on which two softwares are installed and instantiated: ERP5 "Cloud Engine" and a Frontend (Apache) for accessing ERP5. This describes the second reflexive nature of SlapOS: SlapOS is used to deploy SlapOS.
This implementation of SlapOS Master originates from an ERP5 implementation for a Central Bank across eight african countries. The underlying idea was that currency clearing and cloud resource clearing are similar and should therefore be implemented with the same software. Besides that, ERP5 had also demonstrated its scalability for large CRM applications as well as its trustability for accounting. Thanks to NEO, the distributed NoSQL database ERP5 is using, the transactional nature and scalability which is required for a stateful marketplace could be implemented in ERP5.
Developing SlapOS Master on top of ERP5 also was a direct application of ERP5's Universal Business Model (UBM), a model which unifies all sciences of management and which has been acknowledged by numerous IEEE publications as a major shift in enterprise application design. In the UBM, each computer is represented by an Item while allocation requests, resource deliveries and resource accounting are represented by a Movement. The movement resource can be software hosting, CPU usage, disk usage, network usage, RAM usage, login usage, etc. Software hosting movements start whenever the running software starts in the computer partition and stop whenever the running software stops. Resource usage movements start and stop for accounting during each period of time, independently of the running software's state. The software release which is run on a computer partition is an Item in UBM, just like the subscription contract identifier. The parties (client, supplier) are represented as Node. More surprisingly, each Network is also considered a Node in the same way a storage cell is represented as Node in logistics.
Slave Node - Software

SlapOS Slave software consists of a POSIX operating system, SlapGRID, Supervisord and Buildout and is designed to run on any OS that supports GNU's GlibC and Supervisord (eg. GNU/Linux, FreeBSD, MacOS/X, Solaris, AIX et al.) At the time of writing, Microsoft Windows was partially supported (node only) through a GlibC implementation on Windows and a port of Supervisord to Windows.
SlapGRID
SlapGRID acts as the "glue" between the SlapOS Master and both Buildout and Supervisord. SlapGRID requests to SlapOS Master which software should be installed and executed. It uses Buildout to install software and Supervisord to start and stop software processes. SlapGRID also collects the usage data produced by each running software and transmits it to the SlapOS Master.
Supervisord
Supervisord is a process control daemon. It can be used to programmatically start and stop processes with different users, handle their output, log files, errors, etc. It is sort of an improved init.d which can be remotely controlled. Supervisord is lightweight and old enough to be really mature (i.e. no memory leaks).
Buildout
Buildout is a Python-based system for creating, assembling and deploying applications from multiple parts, some of which may be non Python-based. It allows to create Buildout configurations from which the same software can (later) be reproduced. Buildout originated from the Zope/Plone community to automate deployment of customized instances of their own software and has become a stable and mature software over the years. Please refer to understanding Buildout for a more detailed analysis of Buildout and why it is critical to the architecture of SlapOS.
SlapOS Protocol
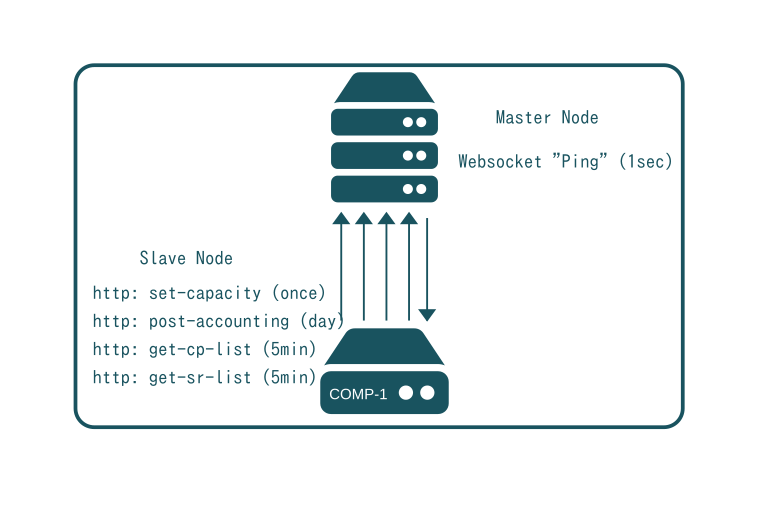
SlapOS is based on the SLAP protocol, a polling protocol every SlapOS slave node uses to contact the Master over http(s) for four different purposes:
- to define capacity
- to collect the list of software to install
- to collect the list of computer partitions to configure
- to post accounting/usage information
At boot time a node contacts the Master specified during installation and notifies it of the boot process having completed. It also provides a list of available computer partitions, their identifiers and IPv6 addresses. This set capacity request is retriggered every 24 hours to take (unlikely) network configuration changes into account.
Every 5 minutes, a node requests the list of software which should be installed. As SlapOS nodes and the SLAP protocol are supposed to be stateless, the values which are exchanged are Promises to reach, not actions to take (see understanding SlapOS Promises). The SlapOS Master thus returns the complete list of softwares which are expected to be installed on the node without taking into account whether such software was installed or not. Reversely, if an installed software is no longer in the list, it implies that it should be removed.
Every 5 minutes, the SlapOS Slave node also requests the list of computer partitions to configure. It is handled by a different process, because installing software could take between a couple of minutes (precompiled and cached) to a couple of hours (recompile for architecture), while configuration should take only a couple of seconds or less. Each request of the list of computer partitions will eventually lead to a reconfiguration of all partitions. If a larger server contained 300 partitions and the configuration of a partition took one second, it will already take five minutes to reconfigure all partitions. Obviously, SlapGRID tries to optimize partition configuration and will only update those partitions which have changed since the last run. Still, in case of an incident of a scale that requires the undesirable configuration of all partitions on a server the configuration is run on a single thread and process to ensure the system does not collapse and most cores of the server are available for running what they are supposed to instead of configuration software.
Once per day, accounting/usage information is collected from every computer partition. It is the role of the software instance running in the computer partition to produce a file which contains usage and incident reports in TioXML format. All files are aggregated and posted to SlapOS Master which then processes them to generate accounting and billing information. The accounting information being exchanged can be very abstract covering both physical usage (CPU, RAM, disk et al), virtual usage (number of users, number of transactions and incidents (failure to access data for x seconds). TioXML format is easy to extend in order to cover any possible billing requirement.
At time of writing, an extension of get-cp-list request using HTTP long-polling or Web Sockets is being considered to make the system more reactive and poll the SlapOS Master less frequently. Still, the goal of the Slap Protocol will likely never consist of providing instant cloud resources. This should rather be done in a predictive pre-allocation approach based on previsions or safety rather than on demand. Along these lines the slowing down of provisioning of a resource may be useful to mitigate the risk of speculation on availability of a cloud resource and thus an efficient way to increase overall cloud resilience. Besides this it needs to be seen whether more scalability can be reached through a HTTP-based push protocol and whether such a protocol can resist frequent network interruptions over intercontinental internet transit routes.
Computer Partition Profile
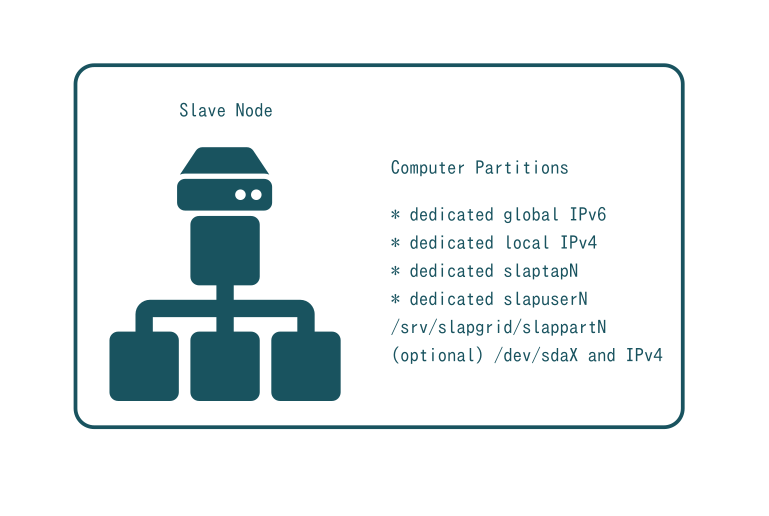
Every computer partition consists of a dedicated IPv6 address, a dedicated local (internal) IPv4 address, a dedicated tap interface (slaptapN), a dedicated user (slapuserN) and a dedicated directory (/srv/slapgrid/slappartN). Optionally, a dedicated block device and routable IPv4 addresses can be defined.
SlapOS is normally configured to use IPv6 addresses. Although it is not a requirement, IPv6 greatly simplifies the deployment of SlapOS for both public and private cloud applications. In private setups, IPv6 helps interconnecting SlapOS slave nodes without having to setup tunnels of complex port redirections. In the public case, IPv6 replaces existing corporate tunnels with a more resilient protocol and a wider, flat address space. IPv6 addressing can help allocating hundreds of IPv6 addresses on a single machine. Each running service can thus be attached to a different IPv6 address without having to change its default port settings also simplifying accounting for network traffic per computer partition.
All this would be possible with IPv4 or through VPNs but it would be more complex and less resilient aside from IPv4 address exhaustion preventing allocation of so many public IPv4 addresses on a single computer.
Even though IPv6 is used to interconnect processes globally on a SlapOS public or private cloud, it was discovered that most existing software is incompatible with IPv6 at the time of writing. Reasons vary from IP addresses being stored in a structure of 3 integers to IPv6 URLs not being recognized due to not relying on a dot separator. For these reasons each computer partition has a dedicated local, non routable IPv4 address.
Legacy software will listen on this IPv4 adress with a proxy mechanism being used to create a bridge between IPv6 and IPv4. In case of an HTTP(s) application, this role is usually played by a Frontend (Apache) which also serves as applicative firewall (mod_security) and security setter (TLS). For other protocols, Stunnel is used for the same purpose (see following sections for details).
For yet another type of applications, IP is not the appropriate ISO level. In these cases, a tap interface is provided emulating a physcial Ethernet interface. This interface is usually bridged with one of the servers' physical Ethernet interfaces. Tap is often used by virtualization software such as KVM to provide access to the outer world network (as it is the case with KVMs provided by SlapOS). But tap can also be used for other applications such as virutal private networks or virtual switches which require direct Ethernet access. On a computer with 100 partitions, tap interfaces are usually named slaptap0, slaptap1,...slaptap99.
...
Every computer partition is linked to a user and a directory. In a computer with 100 partitions, users are named slapuser0, slapuser1, ...slapuser99 and directories /srv/slapgrid/slappart0, /srv/slapgrid/slappart1,.../srv/slapgrid/slappart99.
Directory /srv/slapgrid/slappart0 is then owned by user (or group) slapuser0 and so on. slapuser0 is able to access files in /srv/slapgrid/slappart0 whereas slapuser1 is not able to access the same files, as he only has access to files stored in /srv/slapgrid/slappart1. Moreover, tap interface slaptap0 is owned by slapUser0, tap interface slaptap1 by slapuser1 and so on.
For some applications, it might be necessary to attach certain partitions to a raw block device to maximize disk I/0 performance under certain KVM configurations and to access a physical partition of an SSH disk directly. This possibility has been included in the design of SlapOS although at the time of writing it has not been fully implemented.
Computer partitions are thus configured to not have access to any information on another computer partition. Access rights in SlapOS have three different levels: global access, computer partition only access and superuser only access. SlapOS slave nodes are normally configured in such a way that global hardware status has global access rights and therefore installing monitoring software is possible without further customization.
Every software running on a computer partition has access to all files of the computer partition, owned by the same user. Software running in a computer partition has no possibility to access or modify files owned by the superuser. As a general design rule, SlapOS refuses to grant any superuser privilege to applications or computer partitions. Only SlapGRID and Supervisord are executed with superuser privilege.
Computer Partition Processes
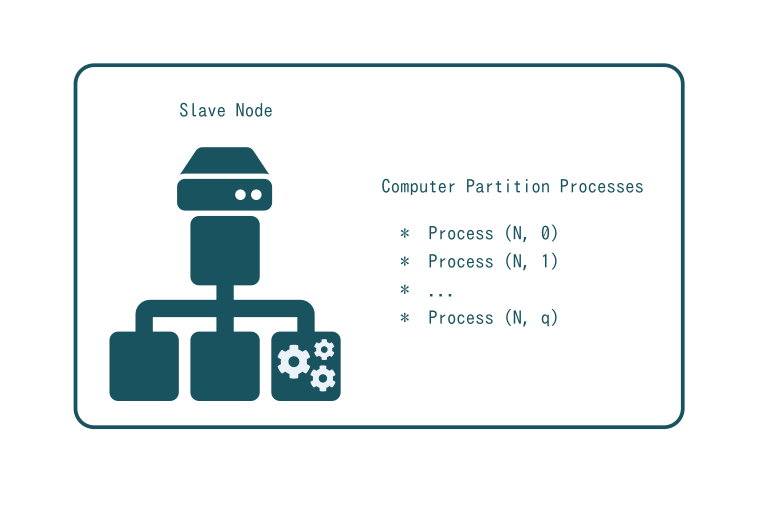
A single computer partition is supposed to host a single application such as a database, an application server or a test runner. Yet, multiple UNIX processes maybe required for this purpose. In case of a Zope Web Application server, at least two processes are needed: a Frontend (Apache) for security (firewall, mod_security, mod_ssl) and a process for the Zope server itself. In case of a database, one process is the database itself and another is a Stunnel application which maps IPv6 ports to local IPv4 ports.
But the number of processes can be higher. Running ERP5 requires at least 12 processes: backend_apache, certificate_authority, conversion_server, crond, erp5_update, kumo_gateway, kumo_manager, kumo_server, memcached, mysql_update, mysqld, zope_1. In this case, the computer partition acts as a "one place fits all" container for ERP5 and its dependencies. A similar approach would be followed for any shrinked wrapped application including Apache/PHP/MySQL apps. This is acceptable because the concept of "elementary" still relates to the idea that only one instance of the application is launched and that most of the time is not used. Multiple computer partitions can thus be allocated on a single computer ignoring the need for scaling up the application.
Some users use a single partition to run multiple instances of the same application server. In this case a computer partition is no longer elementary and acts as a mini-cluster consuming all resources of a computer preventing both the scalability and the possibility to optimize resources usage across SlapOS through fine-grained resource allocation.
IPv6 in SlapOS
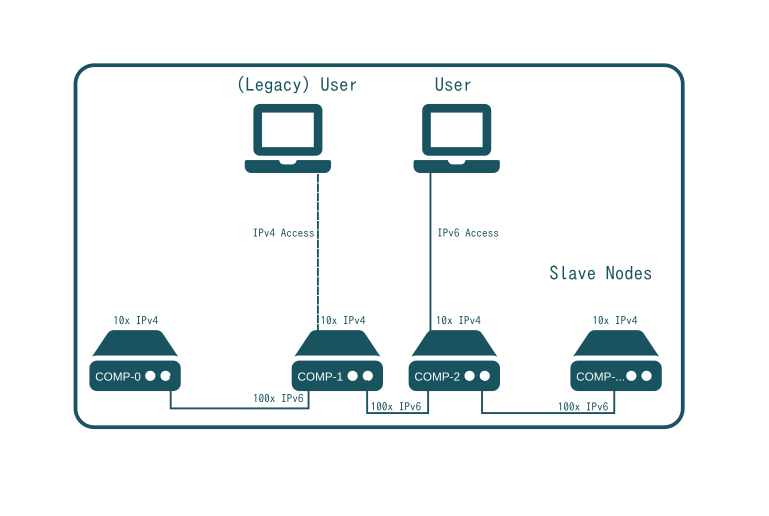
IPv6 is recommended for creating a global, distributed, peer-to-peer, unencrypted network of intercommunicating processes with a single, flat addressing space. In an ideal SlapOS implementation, all software instances allocated on computer partitions of Slave nodes can communicate with each other through IPv6 connections. In addition, some users (represented by laptops) access SlapOS processes using IPv6 directly (eg developers not going through a front end). However, most users will access SlapOS application processes through IPv4 and application Frontends and because of that Frontends are allocated on special computer partitions with dual IPv4 and IPv6 addressing.
For end users, IPv4 Frontends provide access to the IPv6 backend making the use of IPv6 transparent. On the other hand, developers can setup IPv6 tunnels using Miredo or tunnel brokers such as Hurricane Electric. Until now, SlapOS IPv6 could be implemented on any condition incurred. In the worst case, a connection through IPv4 and HTTP to a remote virtual machine hosted on SlapOS and accessible through a Frontend can act as replacement for a local machine.
In case IPv4 is mandatory, IPv6 can be replaced as long as a VPN is deployed to provide a global, flat addressing space with enough available addresses. It should be possible to allocate 100 IPv4 addresses on each SlapOS Slave node. Distributed VPN technologies such as Tinc could eventually be integrated at the core of SlapOS to implement a IPv4 flat addressing space without sacrificing the key concept of resource distribution which lies at the core of SlapOS.
Stunnel - Security and Legacy
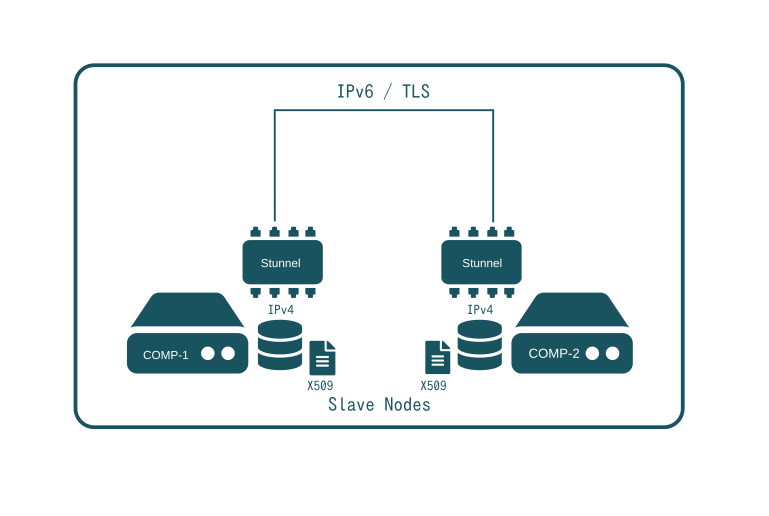
Even today, the main issue with IPv6 is still its poor support and to some degree IPsec. Although IPv6 is a beautiful technology, it is not easy to deploy it in a way that provides encryption and authentication on a per UNIX user base. It is also difficult to deploy in a completely decentralized way.
Stunnel provides a solution to both issues. Whenever secure communication is required between two applications, a Stunnel process is created at both ends. Stunnel maps local IPv4 addresses to global IPv6 addresses and encrypts all communication. Stunnel is also used to restrict access to specific X509 certificates only.
In SlapOS, Stunnel is for example used to connect to MySQL database servers hosted on public IPv6 servers. The MySQL client itself only partially supports IPv6 and does not encrypt connections. With Stunnel, it is possible to access MySQL over IPv6 with encryption and possibly strong authentication. The same approach is used to access Memcached servers. Memcached was originally designed for trustable Local Area Network (LAN). By encapsulating the Memcached protocol into Stunnel, it is possible to support IPv6, encryption and authentication with Memcached.
When developing SlapOS, most software components used by large web infrastructure applications such as social networks, SaaS providers or search engines were designed for trustable environments and private clusters. Porting those applications to distributed cloud and untrustable networks requires significant additional effort to make the connection secure. Rather than using a centralized VPN approach, SlapOS opted to use Stunnel as efficient, peer-to-peer VPN which allowed at the same time to solve the IPv6 migration issue.
Stunnel itself provides enough performance compared to available IP network transit bandwidth. According to the Stunnnel authors, Stunnel performance can reach up to 5.5Gbit/s the time of writing.